
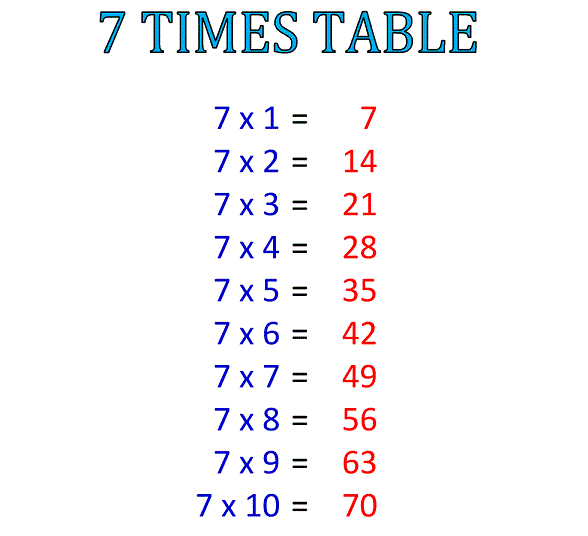
The multiplication table is one of the core requirements that a student should possess in order to master the fundamentals of Mathematics. Today we are going to talk about the table of number 7. Number 7 is a prime number because it has only two factors- 1 and 7 itself. 7 is also an odd number as it is not divided by two. By knowing the table of 7, we can find all the numbers whose prime factor is 7.
7 Table
The Table of number 7 is important to learn as it helps in the faster calculation of specific questions. For that purpose, the table of number 7 is given below. Students who are studying in Class 3 and above can refer to the table of 7 to memorize it. Competitive exam aspirants too can learn the tables from here. It is important to learn tables as it will help drastically in improving the time limit one takes to calculate. Even a second saved from the calculation in competitive exams can decide your rank.
This is the sole reason why we recommend our readers memorize the table of 7 in Mathematics.
Fun Fact: Seven is an odd number and a prime number. It is also a Mersenne prime.
Table of 7
| 7 | * | 1 | = | 7 |
| 7 | * | 2 | = | 14 |
| 7 | * | 3 | = | 21 |
| 7 | * | 4 | = | 28 |
| 7 | * | 5 | = | 35 |
| 7 | * | 6 | = | 42 |
| 7 | * | 7 | = | 49 |
| 7 | * | 8 | = | 56 |
| 7 | * | 9 | = | 63 |
| 7 | * | 10 | = | 70 |
| 7 | * | 11 | = | 77 |
| 7 | * | 12 | = | 84 |
| 7 | * | 13 | = | 91 |
| 7 | * | 14 | = | 98 |
| 7 | * | 15 | = | 105 |
| 7 | * | 16 | = | 112 |
| 7 | * | 17 | = | 119 |
| 7 | * | 18 | = | 126 |
| 7 | * | 19 | = | 133 |
| 7 | * | 20 | = | 140 |
7 ka Table
| 7 | * | 1 | = | 7 |
| 7 | * | 2 | = | 14 |
| 7 | * | 3 | = | 21 |
| 7 | * | 4 | = | 28 |
| 7 | * | 5 | = | 35 |
| 7 | * | 6 | = | 42 |
| 7 | * | 7 | = | 49 |
| 7 | * | 8 | = | 56 |
| 7 | * | 9 | = | 63 |
| 7 | * | 10 | = | 70 |
| 7 | * | 11 | = | 77 |
| 7 | * | 12 | = | 84 |
| 7 | * | 13 | = | 91 |
| 7 | * | 14 | = | 98 |
| 7 | * | 15 | = | 105 |
| 7 | * | 16 | = | 112 |
| 7 | * | 17 | = | 119 |
| 7 | * | 18 | = | 126 |
| 7 | * | 19 | = | 133 |
| 7 | * | 20 | = | 140 |
Tips and Trick for 7 Table in Maths
- The number 7 is a prime number so in the 7 times table it does not repeat itself until 7 × 10.
- The number 7 has infinite multiples as it can be multiplied with any whole number
It is important to know the tables even if you are no longer a student. This will help you in calculating numbers in your everyday life. Keep learning and enjoy the process of learning more than focusing on the ultimate goal. Have a great day ahead!
Table of 7 Worksheet
Below we have provided some problems related to this table. Students should solve the given worksheet y referring to the above table. It will help students understand this concept in a better way.
1) 7 x 6 = _____
2) 7 x ____ = 98
3) 7 x ____ = 14
4) ____ x 7 = 35
5) 7 x 15 = ______
6) 7 x 12 = ______
7) 4 x ____ = 28
Read Some Frequently Used Table for Fast Calculation
| Table of 16 | Table of 17 |
| Table of 23 | Table of 15 |
| Table of 7 | Table of 6 |
| Table of 29 | Table of 21 |
7 Table QNAs
1. Is there a pattern for 7 times table?
Yes, there is a pattern in 7 times table. The pattern is 4, 1, 8, 5, 2, 9, 6, 3, and 0 in the unit’s place
2. Is there a trick for 7 times table?
Yes, there are tricks for 7 times table. Refer to the tips and tricks section to know more.
3. What are the factors of 7?
The factors of 6 are 1, and 7. In negative numbers -1 and -7 are the factors of 7.
4. What is the seventh multiply of 8?
The seventh multiply of 8 is 56.
5. What are the first six multiples of seven?
The first six multiples of 7 are 7, 14, 21, 28, 35, and 42.






 CUET PG Law Important Topics & Weigh...
CUET PG Law Important Topics & Weigh...
 Gujarat NEET Counselling 2026: Registrat...
Gujarat NEET Counselling 2026: Registrat...
 NEET UG 2026 Counselling Dates OUT Soon:...
NEET UG 2026 Counselling Dates OUT Soon:...




